
![[book review] Easy! 딥러닝](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FDkauN%2FbtsL4PevySm%2FAAAAAAAAAAAAAAAAAAAAAIt07N96i1FsjbTl3YftsoWK7dtuq67BvxuDhzNDw720%2Fimg.webp%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DqrYFQMZaDMXlnmmb1uqMmlZcyGU%253D)

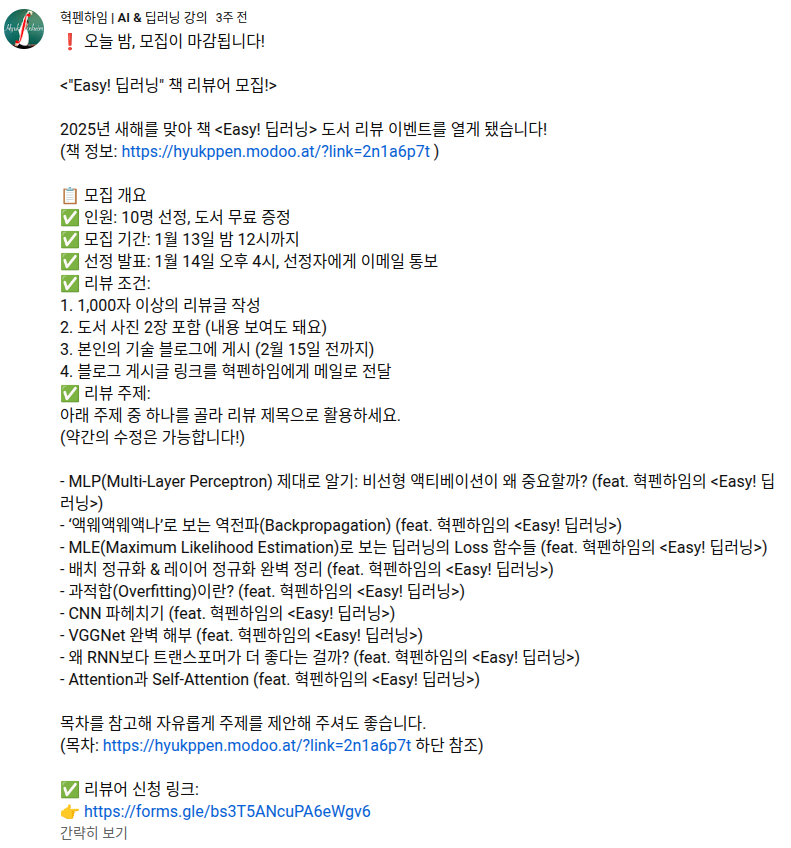
혁펜하임님이 집필하신 <Easy! 딥러닝> 리뷰어로 선정되어 이 글을 작성하게 되었습니다.
혁펜하임님의 대학원 면접 기출 영상과 딥러닝 관련 수학 강의 영상을 재밌고 쉽게 보면서 대학원을 준비하는 과정에서 도움을 많이 받았는데 혁펜하임님의 책을 리뷰할 수 있다는 게 영광입니다.
이런 분들께 추천합니다!
✔️ 딥러닝을 처음 공부하는데 어디서부터 시작해야할 지 막막한 분
✔️ 복잡한 수식을 알기 쉽게 이해하고, 직관적으로 개념을 익히고 싶은 분
유튜브에 "Easy! 딥러닝"을 검색하면 딥러닝 이론 강의를 무료로 보실 수 있습니다. 책을 읽으시다가 추가적인 설명이 필요하다면 영상을 참고하셔도 좋고, 질문도 남길 수 있어 딥러닝을 이해하시는데 어려움이 없을 것 같습니다.
이 책은 현존하는 모든 인공지능 기술의 원리와 배경지식을 알아가고싶은 독자에게 추천하는 필독서로,
딥러닝 공부를 어떻게, 어디서부터 해야할지 모르는 분들이 읽으시면 좋을 것 같습니다.
CNN 톺아보기
최근 인공지능 기술이 발전하면서 CNN(Convolutional Neural Network, 합성곱 신경망)이 주목받고 있습니다. 특히 자율주행, 의료 영상 분석, 얼굴 인식 등 다양한 분야에서 CNN이 활약하고 있는데요. CNN이 무엇인지 알아보겠습니다.
CNN은 FC(Fully connected) layer와는 다르게 "국소적 연결"을 사용한 컨볼루션(Convolution) 연산을 통해 효과적인 이미지 처리를 가능케 합니다.
국소적 연결은 부분적인 정보들을 조합하여 학습을 할 수 있습니다. 이에 대한 장점은 이미지 내의 요소들의 위치 정보를 유지하면서 특정 패턴을 찾아낼 수 있어 정확하게 이미지를 학습하고 인식할 수 있게 합니다.
왜 CNN이 필요할까
기존의 이미지 분석 방법들은 단순한 픽셀 값 비교에 의존하거나 사람이 직접 특징을 정의해야 했습니다. 하지만 이미지 데이터는 수많은 픽셀로 이루어져 있어 이를 직접 다루기엔 한계가 있었습니다. CNN은 "합성곱(convolution)" 이라는 개념을 이용해 이미지의 주요 특징을 자동으로 찾아내고, 이를 활용해 패턴을 학습합니다.
CNN의 주요 구성 요소
컨볼루션 레이어 (Convolutional Layer)
컨볼루션 레이어는 입력 이미지에서 특징을 추출하는 역할을 합니다. 작은 크기의 필터(커널)가 입력 이미지 위를 이동하면서 합성곱 연산(Convolution Operation)을 수행하여 특징 맵(Feature Map)을 생성합니다.
- 필터(Filter): 가중치를 가진 작은 행렬로, 이미지에서 특정 패턴을 감지하는 역할을 합니다.
- 스트라이드(Stride): 필터가 이동하는 간격을 의미합니다. 값이 크면 출력 크기가 작아집니다.
- 패딩(Padding): 입력 이미지 주변을 0으로 채워 크기를 유지하거나 특징 손실을 방지하는 방법입니다.
활성화 함수 (Activation Function)
컨볼루션 연산 후 비선형성을 추가하기 위해 활성화 함수를 적용합니다. 대표적으로 ReLU(Rectified Linear Unit)가 사용됩니다.
- ReLU: 로 정의되며, 기울기 소실(Vanishing Gradient) 문제를 완화하고 학습 속도를 향상시킵니다.
풀링 레이어 (Pooling Layer)
풀링 레이어는 특징 맵의 크기를 줄여 연산량을 감소시키고, 위치 변화에 대한 모델의 일반화 능력을 높입니다.
- 최대 풀링(Max Pooling): 필터 내에서 최댓값을 선택하는 방식으로 주요 특징을 보존합니다.
- 평균 풀링(Average Pooling): 필터 내의 평균값을 계산하여 대표 값을 추출합니다.
완전 연결 레이어 (Fully Connected Layer)
CNN의 마지막 단계에서 완전 연결 레이어를 사용하여 최종 분류 또는 회귀 작업을 수행합니다. 특징 맵을 1차원 벡터로 변환한 후 다층 퍼셉트론(MLP) 구조를 통해 최종 출력을 생성합니다.
드롭아웃 (Dropout)
과적합을 방지하기 위해 뉴런을 랜덤하게 제거하여 학습을 진행하는 정규화 기법입니다.
아래 사진처럼 모델 구조를 그림으로 표현하기도 하고 코드로 나타내주기도 합니다.



기존 레이어가 모든 픽셀을 동시에 고려하려 했던 것과는 달리. CNN은 '선택과 집중'을 통해 이 문제를 해결했습니다. 필터의 웨이트를 공유하고 이미지를 스캔하는 방식으로 패턴을 추출하며, 위치적으로 가까운 노드들의 정보를 먼저 조합한 후 점진적으로 더 넓은 영역의 정보를 통합할 수 있습니다.
결론적으론 CNN의 핵심은 각 픽셀마다 필터의 웨이트를 공유하고 이미지를 스캔하는 방식으로 패턴을 추출하며, 위치적으로 가까운 노드들의 정보를 먼저 조합한 후 점진적으로 더 넓은 영역의 정보를 통합합니다.
이러한 접근 방식은 멀리 있는 픽셀들의 정보도 활용하되, 여러 단계의 정제 과정을 거친 후에 활용하게 됩니다. 이를 통해 CNN은 지역적 특징과 전역적 정보를 모두 효과적으로 통찰할 수 있게 되어 이미지 처리 분야에서 탁월한 성능을 보이게 되었습니다.
하지만 이미지 처리에 있어서 CNN이 가장 우수하다고는 말할 수 없습니다.
CNN도 분명 한계가 존재합니다. 회전이나 크기 변화에 대한 불변성이 부족합니다. 책에 나와있기를,
똑바로 서 있는 고양이 이미지로 학습한 CNN은 거꾸로 된 고양이 이미지를 인식하는 데 어려움을 겪을 수 있다고 합니다.
또한 학습된 크기와 다른 크기의 객체를 인식하는 데에도 제한이 있습니다. 이러한 한계를 극복하기 위해 데이터 증강(augmentation)이나 특수한 구조의 CNN 등 다양한 기법들이 연구되고 있습니다.
왜 CNN이 이미지 데이터에 많이 쓰이는지, CNN 구조가 어떻게 이루어져있는지, CNN의 특징 맵 실험 결과 분석 등을 많은 부분을 책에서 다루고 있으니 읽어보시면 좋을 것 같습니다.
본 게시글은 혁펜하임의 <Easy! 딥러닝> 책의 리뷰어 활동으로 작성되었습니다.
도서 구매 링크 1 (교보문고): https://product.kyobobook.co.kr/detail/S000214848175
도서 구매 링크 2 (출판사 자사몰): https://shorturl.at/yqZpW